Practical-5 Visual Programming With Orange Tool
Visual Programming with Orange Tool
This blog explores more about the Orange tool and explores features like Test/Train splitting, cross-validation techniques, Test & score widgets
Test-Train Split
The train-test split is a technique for evaluating the performance of a machine learning algorithm. It can be used for classification or regression problems and can be used for any supervised learning algorithm. The procedure involves taking a dataset and dividing it into two subsets.
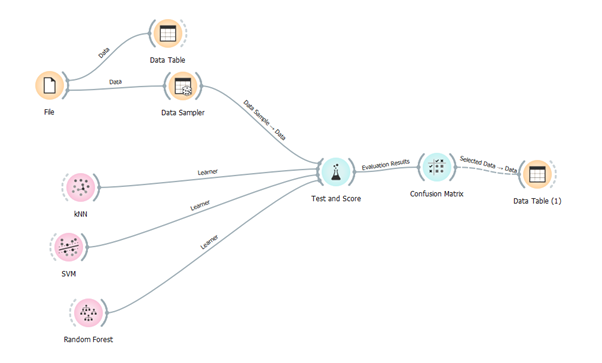
For the Train Test Split, I used the below workflow.
Here I am using the blog, Iris dataset.
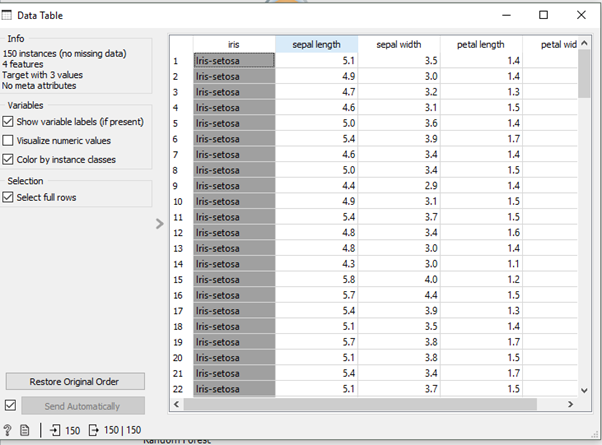
After that, I pass the whole dataset into Data Sampler Widget. In Data Sampler Widget we will partition our dataset into train and test data.

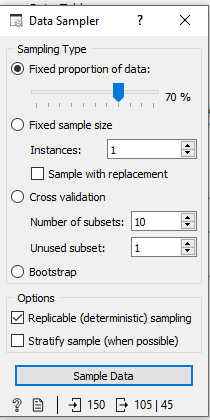
As you can see I split the data into a 70:30 ratio. 70% Train Data and 30% Test Data.
Now after splitting the data I connect Data Sampler with Test & Score Widget. I connect two lines one for train data and another for test data.
Now for model creation, we use the Random Forest algorithm, K-Nearest Neighbor algorithm and SVM
Firstly we evaluate our model on test on test data.
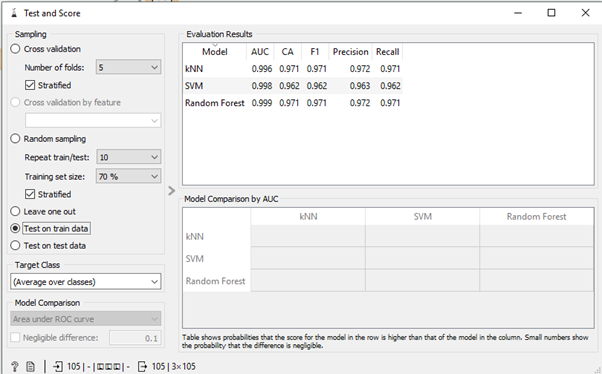
Cross-Validation
Cross-Validation is a statistical method of evaluating and comparing learning algorithms by dividing data into two segments: one is used to learn or train a model and the other is used to validate the model. The basic form of cross-validation is k-fold cross-validation.
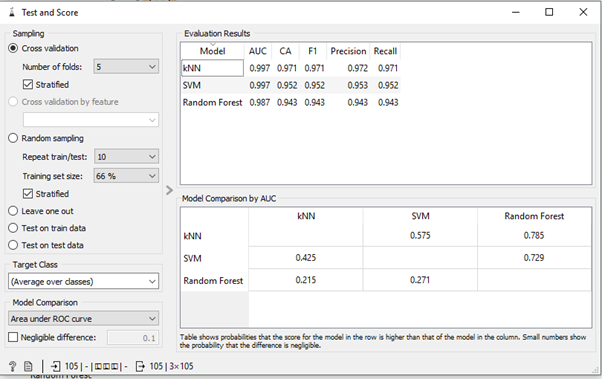
We can do cross-validation using the Test & Score widget. Cross-validation is applied to the entire dataset.
For Cross-Validation I used the following workflow:
Confusion Matrix
A confusion matrix is a table that is often used to describe the performance of a classification model (or “classifier”) on a set of test data for which the true values are known.
After that Test & Score widget connects with the Confusion Matrix in which we can see the result and after that, from the confusion matrix, we can select the data and view it into the Data Table widget .

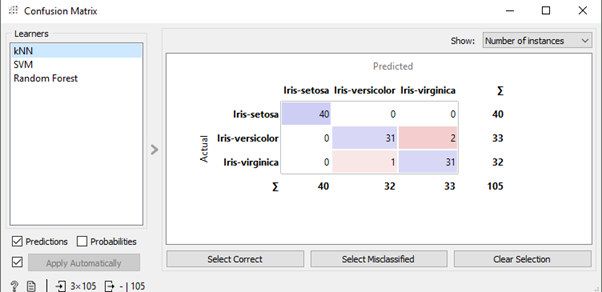
Here we can see the Confusion matrix for kNN, and also we can see for all algorithms.

Comments
Post a Comment