Data Preprocessing
Data Preprocessing
Introduction
Data preprocessing can refer to manipulation or dropping of data before it is used in order to ensure or enhance performance, and is an important step in the data mining process.
Dataset Description
The Iris flower data set or Fisher’s Iris data set is a multivariate data set. The data set consists of 50 samples from each of three species of Iris (Iris setosa, Iris virginica and Iris versicolor). Four features were measured from each sample: the length and the width of the sepals and petals, in centimeters. Based on the combination of these four features, Fisher developed a linear discriminant model to distinguish the species from each other.
Dataset: Iris Data Set
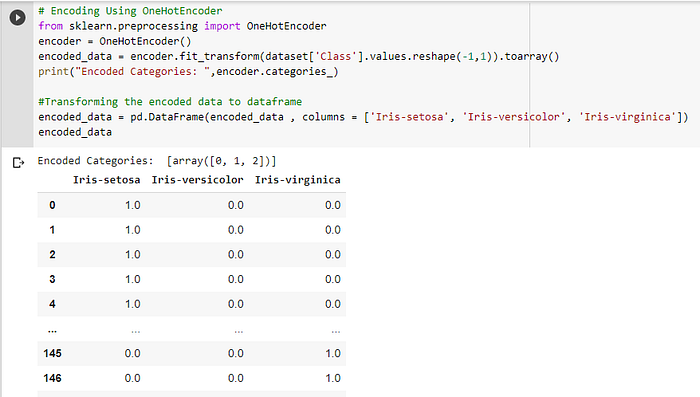
Encoding
Data encoding is the transformation of categorical variables to binary or numerical counterparts. In this we assign unique values to all the categorical attribute. An example is to treat male or female for gender as 1 or 0. so there are two types so data encoding label encoding and Onehot encoding

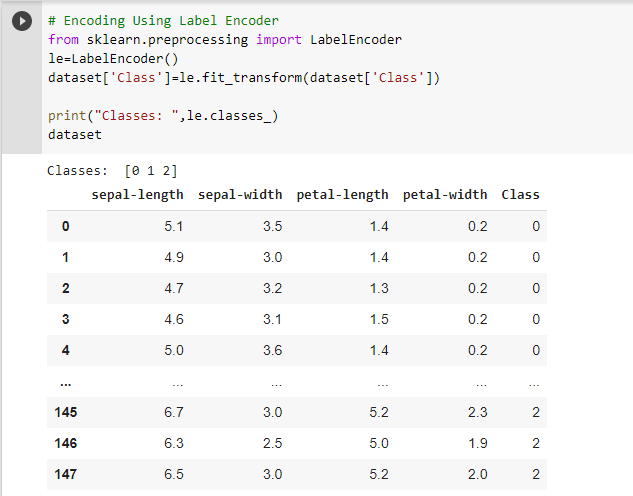
- label encoding: If we will have more than one category in the dataset that to convert those categories into numerical features we can use a Label encoder. Label Encoder will assign a unique number to each category.
2. Onehot encoding
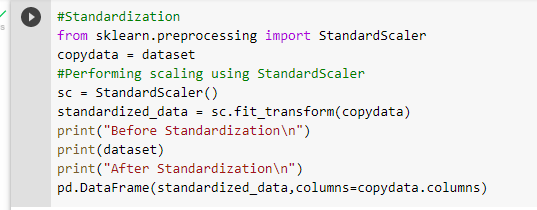
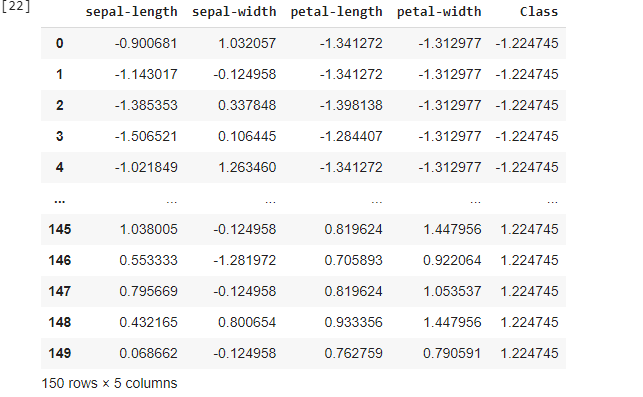
Standardization
Standardization is another scaling technique where the values are centered around the mean with a unit standard deviation. This means that the mean of the attribute becomes zero and the resultant distribution has a unit standard deviation(i.e. standard deviation = 1).



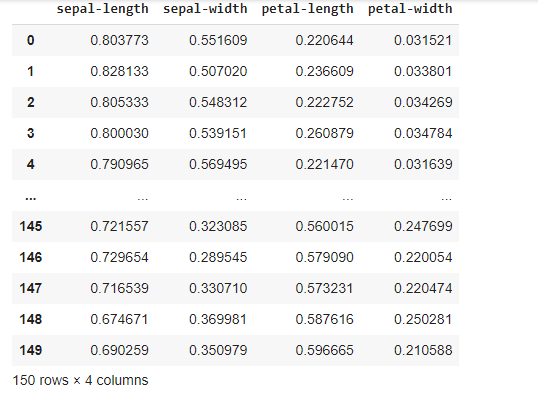
Normalization
Normalization is a scaling technique in which values are shifted and rescaled so that they end up ranging between 0 and 1. because in real-world data is not available on the same scale. Data columns will always have different scales. So to make all the columns in one scale we can use normalization methods.



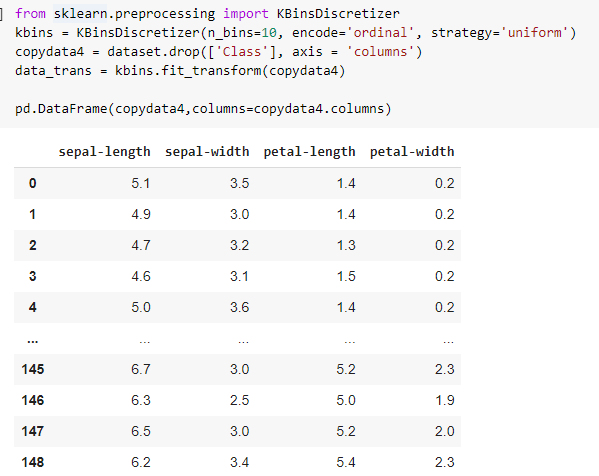
Discretization
Data discretization refers to a method of converting a huge number of data values into smaller ones so that the evaluation and management of data become easy. Discretization (otherwise known as quantization or binning) provides a way to partition continuous features into discrete values. Certain datasets with continuous features may benefit from discretization, because discretization can transform the dataset of continuous attributes to one with only nominal attributes.

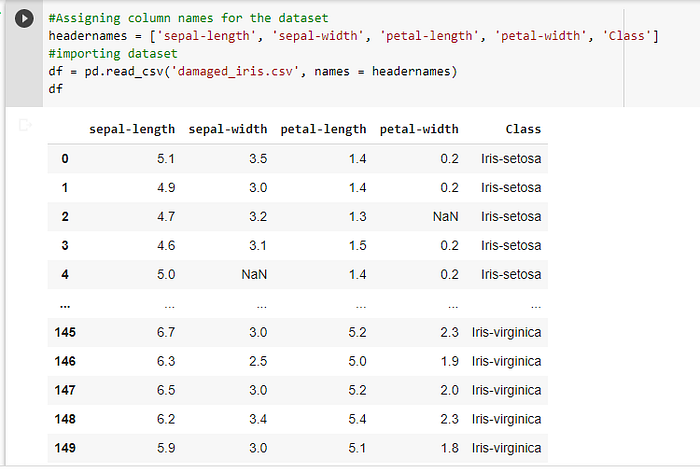
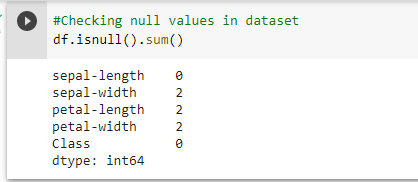
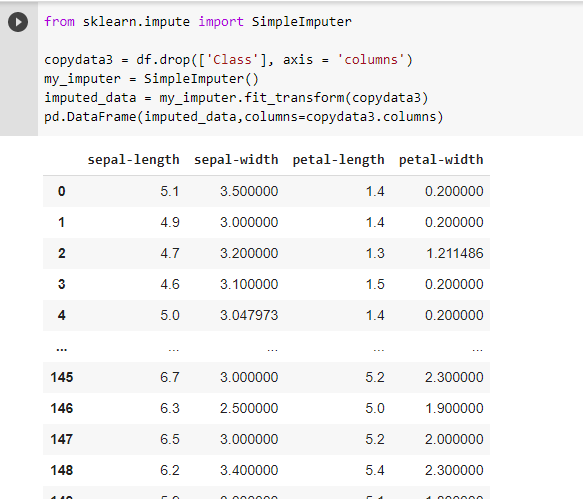
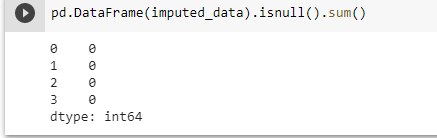
Imputation
For various reasons, many real world datasets contain missing values, often encoded as blanks, NaNs or other placeholders. Such datasets however are incompatible with many estimators which assume that all values in an array are numerical, and that all have and hold meaning. A basic strategy to use incomplete datasets is to discard entire rows and/or columns containing missing values. However, this comes at the price of losing data which may be valuable (even though incomplete). A better strategy is to impute the missing values, i.e., to infer them from the known part of the data.
The SimpleImputer class provides basic strategies for imputing missing values. Missing values can be imputed with a provided constant value, or using the statistics (mean, median or most frequent) of each column in which the missing values are located. This class also allows for different missing values encodings.





Comments
Post a Comment